Python Code Conventions
We use standardized code conventions to ensure uniformity across all Cortex XSOAR Integrations. This section outlines our code conventions.
New integrations and scripts should follow these conventions. When working on small fixes and modifications to existing code, follow the conventions used in the existing code.
Note: Cortex XSOAR supports also JavaScript integrations and scripts. Our preferred development language is Python, and all new integrations and scripts should be developed in Python, which also provides a wider set of capabilities compared to the available JavaScript support. Simple scripts may still be developed in JavaScript using the conventions provided by the default script template used in the Cortex XSOAR IDE.
Example Code and Templates#
For an example of a Hello World integration see HelloWorld.
For quick starts templates see Templates directory.
Python 2 vs 3#
All new integrations and scripts should be written in Python 3. Python 2 is supported only for existing integrations and scripts.
Note: From October 1, 2025, Python 2 will no longer be supported.
Imports#
You define imports and disable insecure warning at the top of the file.
Constants#
You define constants in the file below the imports. It is important that you do not define global variables in the constants section.
IMPORTANT: The example below shows the incorrect way to name constants.
Main function#
These are the best practices for defining the Main function.
- Create the
mainfunction and in the main extract all the integration parameters. - Implement the _command function for each integration command (e.g.,
say_hello_command(client, demisto.args())) Note that it's strongly not recommended to use dictionary deconstruction (e.g.,**args) as it may introduce bugs to the command execution in certain flows. - To properly handle exceptions, wrap the commands with try/except in the main. The
return_error()function receives error message and returns error entry back into Cortex XSOAR. It will also print the full error to the Cortex XSOAR logs. - For logging, use the
demisto.debug("write some log here")function. - In the main function, initialize the Client instance, and pass that client to
_commandfunctions.
Client class#
These are the best practices for defining the Client class.
- Client should inherit from BaseClient. BaseClient defined in CommonServerPython.
- Client is necessary in order to prevent passing arguments from one function to another function, and to prevent using global variables.
- Client will contain the
_http_requestfunction. - Client will implement the 3rd party service API.
- Client will contain all the necessary params to establish connection and authentication with the 3rd party API.
Example - client instance using API KEY#
Example - client instance using Basic Authentication#
HTTP Call Retries#
We do not allow using sleep in the code as it might lead to performance issues.
Instead, you can utilize the retry mechanism implemented in the BaseClient by using the retries and backoff_factor arguments of the _http_request function.
Command Functions#
These are the best practices for defining the command functions.
- Each integration command should have a corresponding
_commandfunction. - Each _command function should use
Clientclass functions. - Each _command function should be unit testable. This means you should avoid using global functions, such as
demisto.results(),return_error(), orreturn_results(). - The _command function will receive
clientinstance andargs(demisto.args()dictionary). - The _command function will return an instance of the CommandResults class.
- To return results to the War Room, in the
mainusereturn_results(say_hello_command(client, demisto.args())).
IOC Reputation Commands#
There are two implementation requirements for reputation commands (aka !file, !email, !domain, !url, and !ip) that are enforced by checks in the demisto-sdk.
- The reputation command's argument of the same name must have
defaultset toTrue. - The reputation command's argument of the same name must have
isArrayset toTrue.
For more details on these two command argument properties look at the yaml-file-integration in our docs folder.
test-module#
- When users click the Test button, the
test-modulewill execute when the Test button pressed in the integration instance setting page. - If the test module returns the string
"ok"then the test will be green (success). All other string will be red.
fetch-incidents#
These are the best practices for defining fetch-incidents.
- The fetch-incidents function will be executed when the
Fetch incidentscheckbox is selected in the integration settings. This function will be executed periodically. - The fetch-incidents function must be unit testable.
- Should receive the
last_runparam instead of executing thedemisto.getLastRun()function. - Should return
next_runback to main, instead of executingdemisto.setLastRun()inside thefetch_incidentsfunction. - Should return
incidentsback to main instead of executingdemisto.incidents()inside thefetch_incidentsfunction.
Exceptions and Errors#
These are the best practices for defining the exceptions and errors.
- To avoid unexpected issues, it is important to wrap your command block in a "Try-Catch". See the example below.
- Raise exceptions in the code where needed, but in the main catch them and use the
return_errorfunction. This will enable acceptable error messages in the War Room, instead of stack trace. - If the
return_errorsecond argument is error, you can pass Exception object. - You can always use
demisto.error("some error message")to log your error.
Unit Tests#
Every integration command must be covered with a unit test. Unit tests should be documented using Given-When-Then.
- Unit tests must be in a separate file, which should have the same name as the integration but be appended with
_test.pyfor exampleHelloWorld_test.py - To mock http requests use requests_mock.
- For mocks use mocker.
For example:
Variable Naming#
When naming variables, use [snake_case]([url](https://en.wikipedia.org/wiki/Snake_case)), not PascalCase or camelCase.
Outputs#
Make sure you read and understand Context and Outputs.
Make sure you follow our context standards when naming indicator outputs.
Linking Context#
Wherever possible, we try to link context together. This will prevent a command from overwriting existing data, or from creating duplicate entries in the context. To do this, observe the following:
In this instance, the val.URL && val.URL == obj.URL links together the results retrieved from this integration with results already in the context where the value of the URL is the same.
For more information about the syntax of linking and Cortex XSOAR Transform Language in general have a look here
Logging#
In some cases, it may be necessary to pass information to the logs to assist future debugging.
First, we need to ensure that the debug level logging is enabled. Go to Settings -> About -> Troubleshooting and select Debug for Log Level.
To post to the logs, we use the following:
You can also use the @logger decorator in Cortex XSOAR. When the decorator is placed at the top of each function, the logger will print the function name as well as all of the argument values to the LOG.
Note: These logging methods replace the deprecated LOG() function.
Do Not Print Sensitive Data to the Log#
This section is critical. When an integration is ready to be used as part of a public release (meaning you are done debugging it), we ALWAYS remove print statements that are not absolutely necessary.
Dates#
We do not use epoch time for customer facing results (Context, Human Readable, etc.). If the API you are working with requires the time format to be in epoch, then convert the date string into epoch as needed. Where possible, use the human readable format of the date %Y-%m-%dT%H:%M:%S
Note: If the response returned is in epoch, it is a best practice to convert it to %Y-%m-%dT%H:%M:%S.
Pagination in Integration Commands#
When working on a command that supports pagination (usually has API parameters like page and/or page size) with a maximal page size enforced by the API, our best practice is to create a command that will support two different use-cases with the following 3 integer arguments:
pagepage_sizelimit
The two use cases
- Manual Pagination: - The user wants to control the pagination on its own by using the
pageandpage sizearguments, usually as part of a wrapper script for the command. To achieve this, the command will simply pass thepageandpage sizevalues on to the API request. Iflimitargument was also provided, then it will be redundant and should be ignored. - Automatic Pagination: - Useful when the user prefers to work with the total number of results returned from the playbook task rather than implementing a wrapper script that works with pages. In this case, the
limitargument will be used to aggregate results by iterating over the necessary pages from the first page until collecting all the needed results. This implies a pagination loop mechanism will be implemented behind the scenes. For example, if the limit value received is 250 and the maximal page size enforced by the API is 100, the command will need to perform 3 API calls (pages 1,2, and 3) to collect the 250 requested results. Note that when a potentially large number of results may be returned, and the user wants to perform filters and/or transformers on them, we still recommend creating a wrapper script for the command for better performance.
Notes:
- Page Tokens - In case an API supports page tokens, instead of the more common 'limit' and 'offset'/'skip' as query parameters:
- The arguments that will be implemented are:
limit,page_sizeandnext_token. - The retrieved
next_tokenshould be displayed in human readable output and in the context. It will be a single node in the context, and will be overwritten each command run:
- The arguments that will be implemented are:
- Standard argument defaults -
limitwill have a default of '50' in the YAML.page_sizeshould be defaulted in the code to '50', in case onlypagewas provided. - There should be no maximum value for the
limitargument. This means that users should be able to retrieve as many records as they need in a single command execution. - When an integrated API doesn't support pagination parameters at all - then only
limitwill be applied, and implemented internally in the code. An additional argument will be added to allow the user to retrieve all results by overriding the defaultlimit:all_results=true. - If API supports only 'limit' and 'offset'/'skip' as query parameters, then all 3 standard XSOAR pagination arguments should be implemented.
Credentials#
When working on integrations that require user credentials (such as username/password, API token/key, etc..) the best practice is to use the credentials parameter type.
Using username and password:
In Demisto UI:
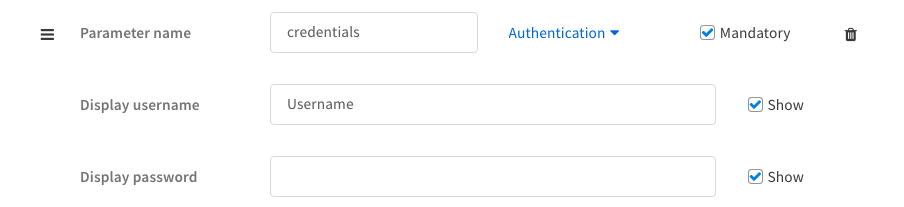
In the YML file:
- And in the code:
- In demistomock.py:
Using an API Token/Key:
In Demisto UI:
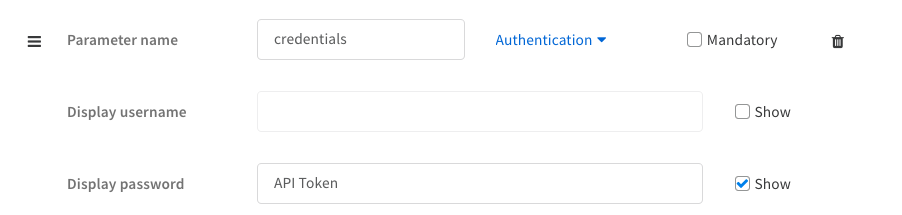
In the YML file:
Using credentials parameter type is always recommended (even when working with API token\key) as it provides the user the flexibility of using the XSOAR credentials vault feature when configuring the integration for the first time.
The hiddenusername configuration key is supported from XSOAR version 6.0.2 and newer. In earlier versions the username field will be visible so we recommend letting the user know this is not mandatory.
Common Server Functions#
Before writing a function that seems like a workaround for something that should already exist, check the script helper to see if a function already exists. Examples of Common Server Functions are noted below:
fileResult#
This will return a file to the War Room by using the following syntax:
You can specify the file type, but it defaults to "None" when not provided.
create_indicator_result_with_dbotscore_unknown#
Used for cases where the API response to an indicator is not found and returns a verdict with an unknown score (0). A generic response is returned to the War Room and to the context path, by using the following syntax:
The War Room result will show:

The Context Path will show:
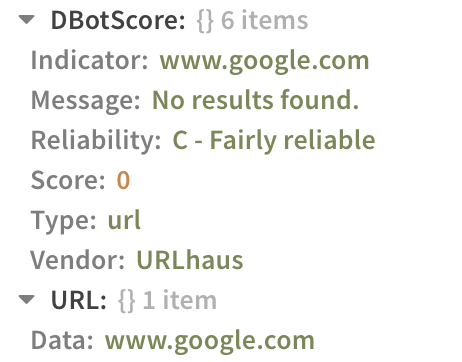
If the integration has a reliability it should be noted, but it defaults to "None" when not provided.
Note:
- When the indicator is of type CustomIndicator, you need to provide the context_prefix argument.
- When the indicator is of type Cryptocurrency, you need to provide the address_type argument.
tableToMarkdown#
This will transform your JSON, dict, or other table into a Markdown table.
The above will create the table seen below: | Input | Output | |--------|--------| | first | foo | | second | bar | | third | baz |
In the War Room, this is how a table will appear:
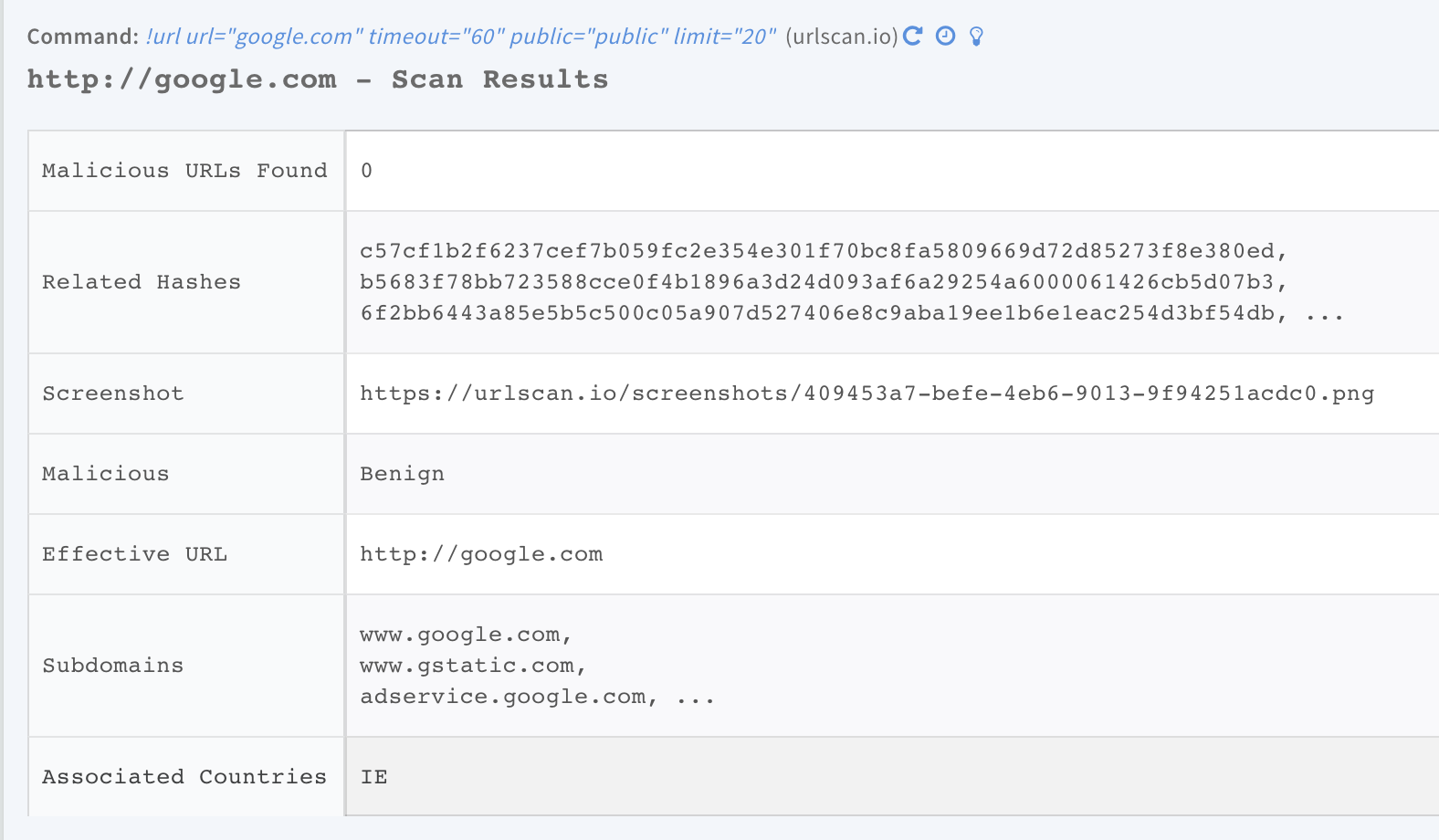 # You may also use ```headerTransform``` to convert the existing keys into formatted headers. |This function formats the original data headers (optional).
# You may also use ```headerTransform``` to convert the existing keys into formatted headers. |This function formats the original data headers (optional).d = { "id": "123", "url1": " https://url1.com", "result": { "files": [ { "filename": "Screen.jpg", "url2": "https://url2.com" } ] }, "links": { "url3": "https://url2.com" } }
The resulted table will be:

Use the date_fields argument (list) of date fields to format the value to human-readable output.
The above will create the table seen below:
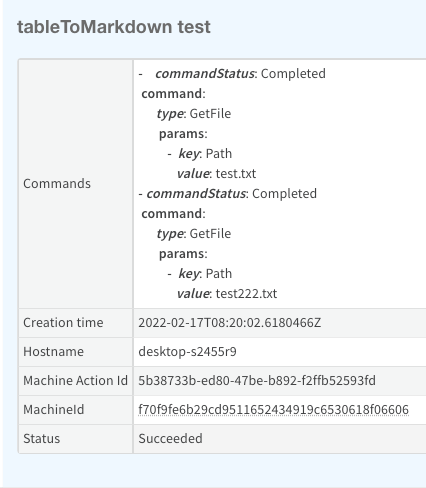
#
Use the is_auto_json_transform argument (bool), to try to auto transform a complex JSON.
The above will create the table seen below:
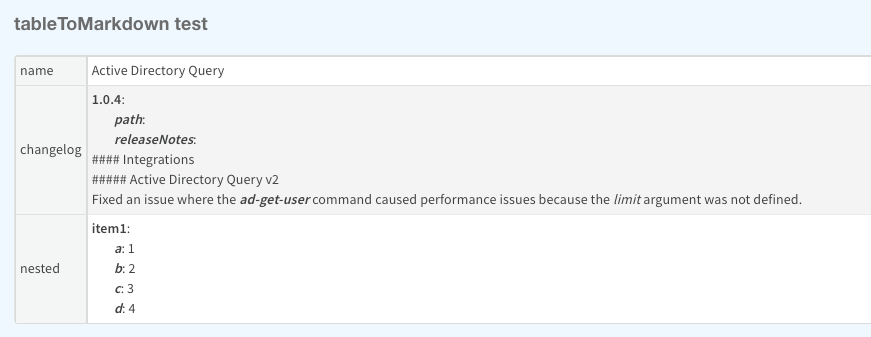
demisto.command()#
demisto.command() is typically used to tie a function to a command in Cortex XSOAR, for example:
demisto.params()#
demisto.params() returns a dict of parameters for the given integration. This is used to grab global variables in an integration, for example:
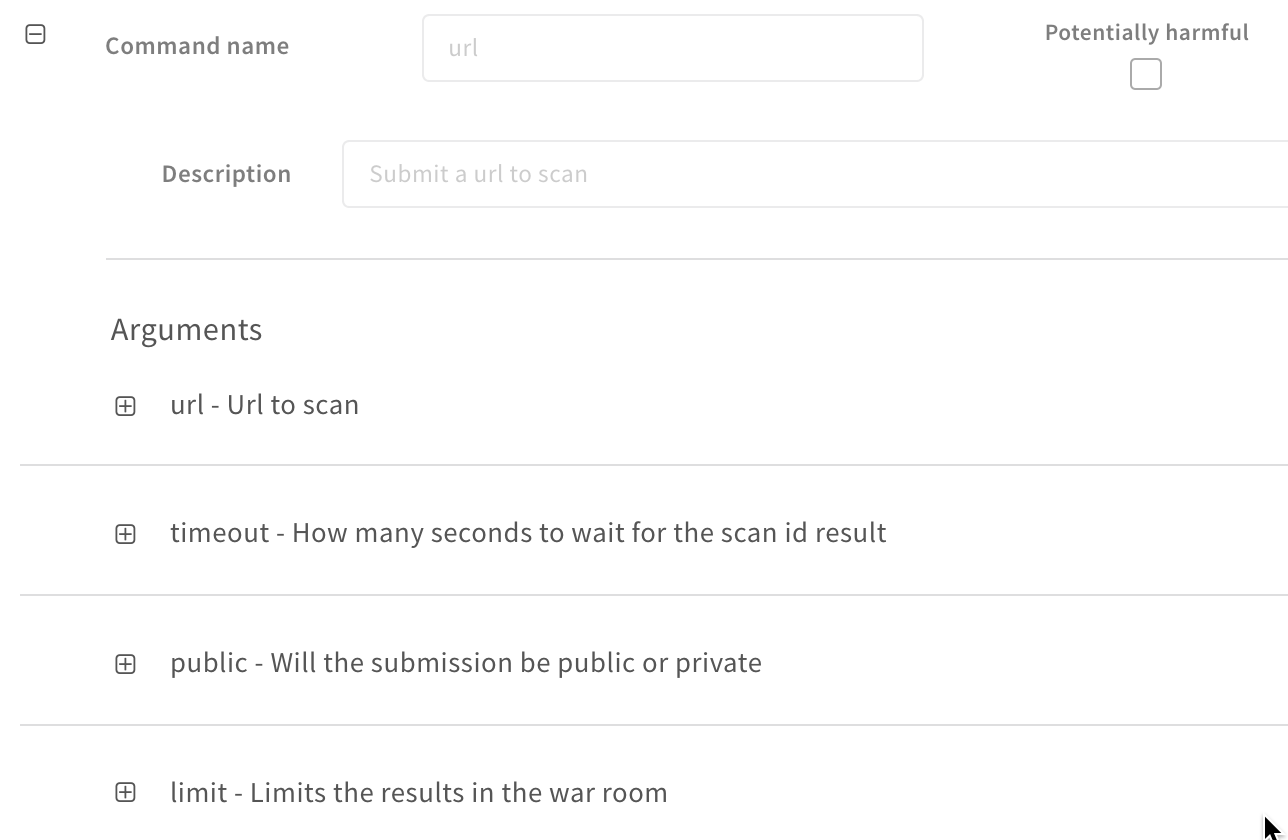
demisto.args()#
demisto.args() returns a dict of arguments for a given command. We use this to get non-global variables, for example:
The argument above can be seen in the integration settings as shown below:
 After the command is executed, the arguments are displayed in the War Room as part of the command, for example:
After the command is executed, the arguments are displayed in the War Room as part of the command, for example: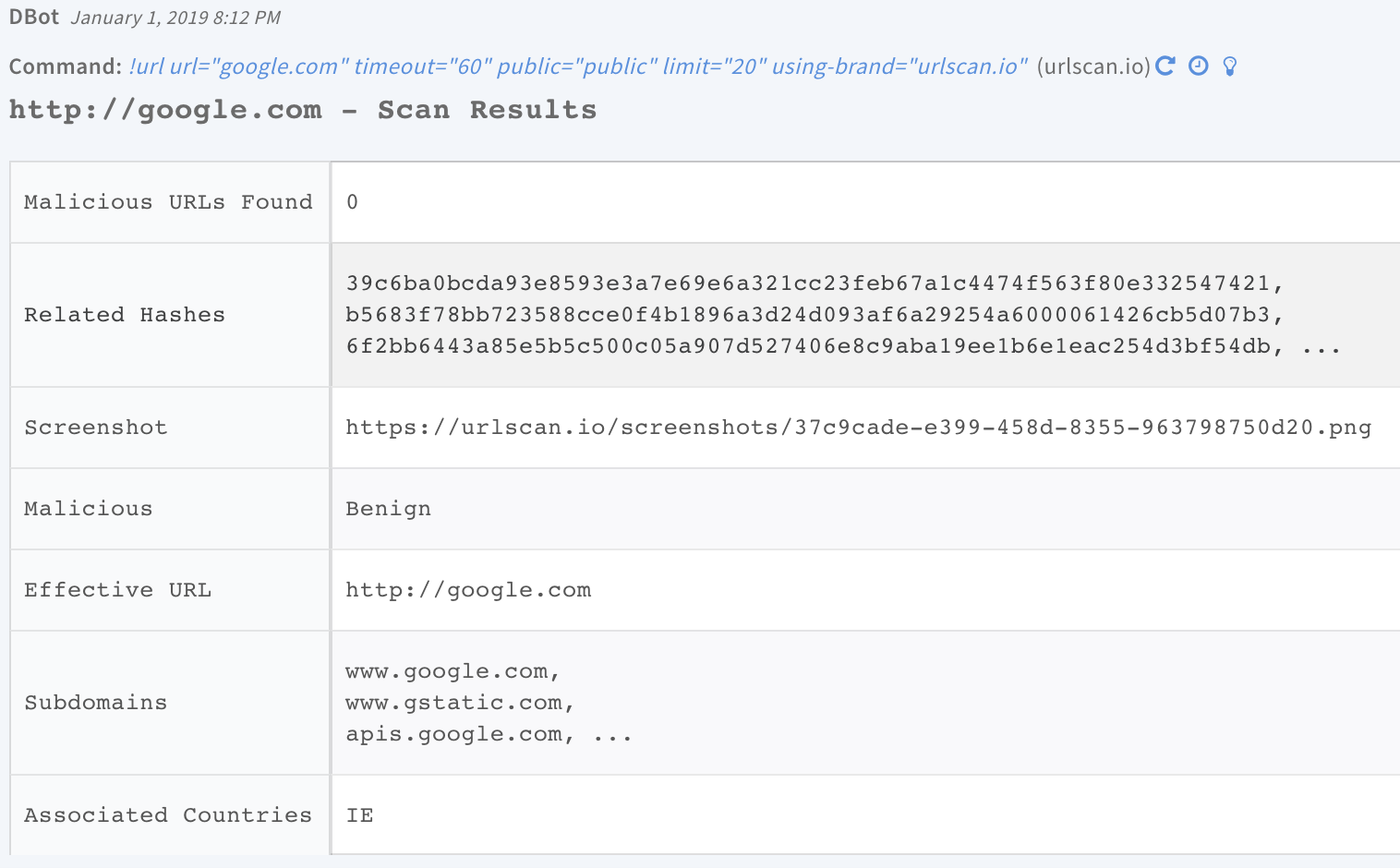
IndicatorsTimeline#
The IndicatorTimeline is an optional object (available from Server version 5.5.0 and up) . It is only applicable for commands that operate on indicators. It is a dictionary (or list of dictionaries) of the following format:
When IndicatorTimeline data is returned in an entry, the timeline section of the indicator whose value was noted in the timeline data will be updated (and is viewable in the indicator's view page in Cortex XSOAR as can be seen in the attached image).
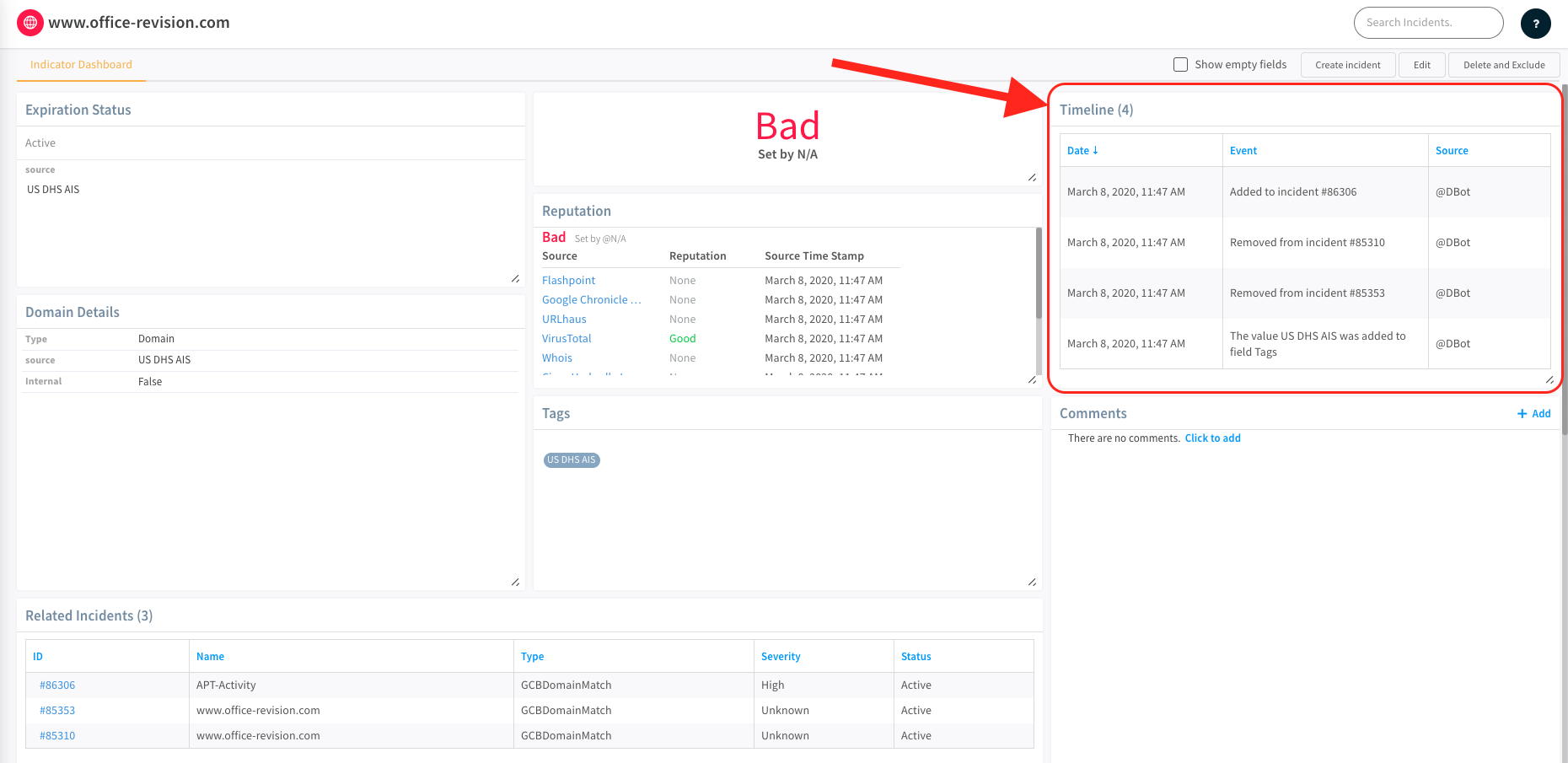
What value should be used for the 'Category' field of a timeline data object?
Any Cortex XSOAR integration command or automation that returns timeline data may include the 'Category' value.
If not given, When returning timeline data from a Cortex XSOAR integration or automation, the value will be 'Integration Update' or 'Automation Update' accordingly.
So when should one include a timeline object in an entry returned to the war room?
The answer is any time that a command operates on an indicator. A good indicator (pun intended?) of when timeline data should be included in an entry is to look and see if the command returns a DBotScore or entities as described in our context standards documentation to the entry context. A common case is reputation commands, i.e. !ip, !url, !file, etc. When implementing these commands in integrations, timeline data should be included in the returned entry. To see an example of an integration that returns entries with timeline data, take a look at our AbuseIPDB integration.
| Arg | Type | Description |
|---|---|---|
| indicators | list | Expects a list of indicators, if a dict is passed it will be put into a list. |
| category | str | Indicator category. |
| message | str | Indicator message. |
Example
CommandResults#
This class is used to return outputs. This object represents an entry in warroom. A string representation of an object must be parsed into an object before being passed into the field.
| Arg | Type | Description |
|---|---|---|
| outputs_prefix | str | Should be identical to the prefix in the yml contextPath in yml file. for example: CortexXDR.Incident |
| outputs_key_field | str | Primary key field in the main object. If the command returns incidents, and one of the properties of the incident is incident_id, then outputs_key_field='incident_id' |
| outputs | list / dict | (Optional) The data to be returned and will be set to context. If not set, no data will be added to the context |
| readable_output | str | (Optional) markdown string that will be presented in the War Room, should be human readable - (HumanReadable) - if not set, readable output will be generated via tableToMarkdown function |
| raw_response | object | (Optional) must be dictionary, if not provided then will be equal to outputs. Usually must be the original raw response from the 3rd party service (originally Contents) |
| indicators | list | DEPRECATED: use 'indicator' instead. |
| indicator | Common.Indicator | single indicator like Common.IP, Common.URL, Common.File, etc. |
| indicators_timeline | IndicatorsTimeline | Must be an IndicatorsTimeline. used by the server to populate an indicator's timeline. |
| ignore_auto_extract | bool | If set to True prevents the built-in auto-extract from enriching IPs, URLs, files, and other indicators from the result. Default is False. |
| mark_as_note | bool | If set to True marks the entry as note. Default is False. |
| relationships | list | A list of EntityRelationship objects representing all the relationships of the indicator. |
| scheduled_command | ScheduledCommand | Manages the way the command result should be polled. |
Example
Note: More examples on how to return results, here
return_results#
return_results() calls demisto.results(). It accept either a list or single item of CommandResults object or any object that demisto.results
can accept.
Use return_results to return mainly CommandResults object or basic string.
Example
Note: More examples on how to return results, here
return_error#
Note: Will return error entry to the warroom and will call sys.exit() - meaning the script will stop.
Will produce an error in the War Room, for example:

CommandRunner#
CommandRunner is a class for executing multiple commands, which returns all valid results together with a human readable summary table of successful commands and commands that return errors.
To use this functionality, create a list of commands using the CommandRunner.Command, and then call CommandRunner.run_commands_with_summary(commands).
CommandRunner.Command:
| Arg | Type | Description |
| ------ | -----| --------|
| commands | str or List[str] | The command to run. Could be a single command or a list of commands. |
| args_lst | dict or List[Dict] | The args of the command. If provided in a list and the commands argument is a str, run the command with all the args in the list. If the commands argument is a list, the args_lst should be in the same size, and the args should correspond to the same command index. |
| instance | str | (Optional) The instance the command should run |
| brand | str | (Optional) The instance the command should run. |
Example
This returns all the results of all commands, including a human readable summary table.
DEPRECATED - demisto.results()#
Note: Use return_results instead
demisto.results() returns entries to the War Room from an integration command or an automation.
A typical example of returning an entry from an integration command looks as follows:
The entry is composed of multiple components.
The
Typedictates what kind of entry is returned to the warroom. The available options as of today are shown in the dictionary keys ofEntryTypebelow.The
ContentsFormatdictates how to format the value passed to theContentfield, the available options can be seen below.The
Contentusually takes the raw unformatted data - if an API call was made in a command, then typically the response from the request is passed here.The
HumanReadableis the textual information displayed in the warroom entry.The
ReadableContentsFormatdictates how to format the value passed to theHumanReadablefield.The
EntryContextis the dictionary of context outputs for a given command. For more information see Outputs.The
IndicatorTimelineis an optional field (available from Server version 5.5.0 and up) . It is only applicable for commands that operate on indicators. It is a dictionary (or list of dictionaries) of the following format:The
PollingCommandruns after the time period (in seconds) designated in theNextRunargument.The
NextRunargument is the next run time in seconds for thePollingCommand. ThePollingCommandexecutes after this time period.The
Timeoutargument is the timeout in seconds for polling sequence command execution. However, if a user has provided anexecution-timeout, it overrides the timeout specified by this field.PollingArgsare the arguments that will be used while running thePollingCommand.When
IndicatorTimelinedata is returned in an entry, the timeline section of the indicator whose value was noted in the timeline data will be updated (and is viewable in the indicator's view page in Cortex XSOAR as can be seen in the attached image).What value should be used for the
'Category'field of atimelinedata object?
Any Cortex XSOAR integration command that returnstimelinedata should include the'Category'value of'Integration Update'. When returningtimelinedata from a Cortex XSOAR automation, the value passed to the'Category'field should be'Automation Update'.So when should one include a timeline object in an entry returned to the war room?
The answer is any time that a command operates on an indicator. A good indicator (pun intended?) of whentimelinedata should be included in an entry is to look and see if the command returns aDBotScoreor entities as described in our context standards documentation to the entry context. A common case is reputation commands, i.e.!ip,!url,!file, etc. When implementing these commands in integrations,timelinedata should be included in the returned entry. To see an example of an integration that returns entries withtimelinedata, take a look at our AbuseIPDB integration.
The EntryType and EntryFormat enum classes are imported from CommonServerPython and respectively appear as follows:
DEPRECATED - return_outputs#
Note: Use return_results instead
return_outputs() is a convenience function - it is simply a wrapper of demisto.results() used to return results to the War Room and which defaults to the most commonly used configuration for entries, only exposing the most functional parameters for the sake of simplicity. For example:
AutoExtract#
As part of CommandResults() there is an argument called ignore_auto_extract, which prevents the built-in indicator extraction feature from enriching IPs, URLs, files, and other indicators from the result. For example:
Note: By default, ignore_auto_extract is set to False.